
We are committed to protecting your personal data and providing you with access to your personal data in accordance with the personal data protection laws in force in the European Union. We have updated and will periodically update our privacy policy to comply with this personal data protection law. Please refer to the latest version of our Privacy Statement.
This website uses cookies to provide a better browsing experience. To learn more about how cookies are used on this site please click here.
16.03
2025
Edgestar Inference Performance Test: Ollama Inference Server Performance with Llama3.1, Qwen2.5, and Deepseek-r1
Edgestar Inference Performance Test: Ollama Inference Server with Llama3.1, Qwen2.5, and Deepseek-R1

As the application of large language models (LLMs) in enterprises grows, selecting the right model is crucial for achieving high performance and reducing costs. Spingence’s Edgestar platform, as a high-performance edge inference solution, helps enterprises deploy and run various LLMs locally, ensuring exceptional performance across different use cases.
This article delves into the inference performance of the Edgestar platform using Ollama across different language models (Llama3.1, Qwen2.5, Deepseek-R1) and tests their performance under varying concurrent request levels. It aims to help you understand how to select the most suitable model to enhance your enterprise applications.
Test Environment and Conditions|

LLM Inference Efficiency Metrics
When conducting inference tests, we focus on three key performance indicators:

- TTFT (Time to First Token): The time taken from sending the request to receiving the first token, which is a key indicator of model response speed.
- End-to-End Latency: The total time taken from the start of the request to the completion of the entire inference process, reflecting the model's overall processing delay.
- FPS (Frames Per Second): The number of requests processed per second, which is a crucial metric for evaluating the system’s processing capability and throughput.
These metrics help assess the performance of different types of LLMs in a hardware environment and understand their operational efficiency in real-world applications.
LLM Inference Efficiency with Single Requests
Based on the parameter scale of the models, LLMs are divided into three categories: Lightweight Applications (less than 10B parameters), Medium-Scale Applications (less than 50B parameters) and Heavyweight Applications (greater than 70B parameters)
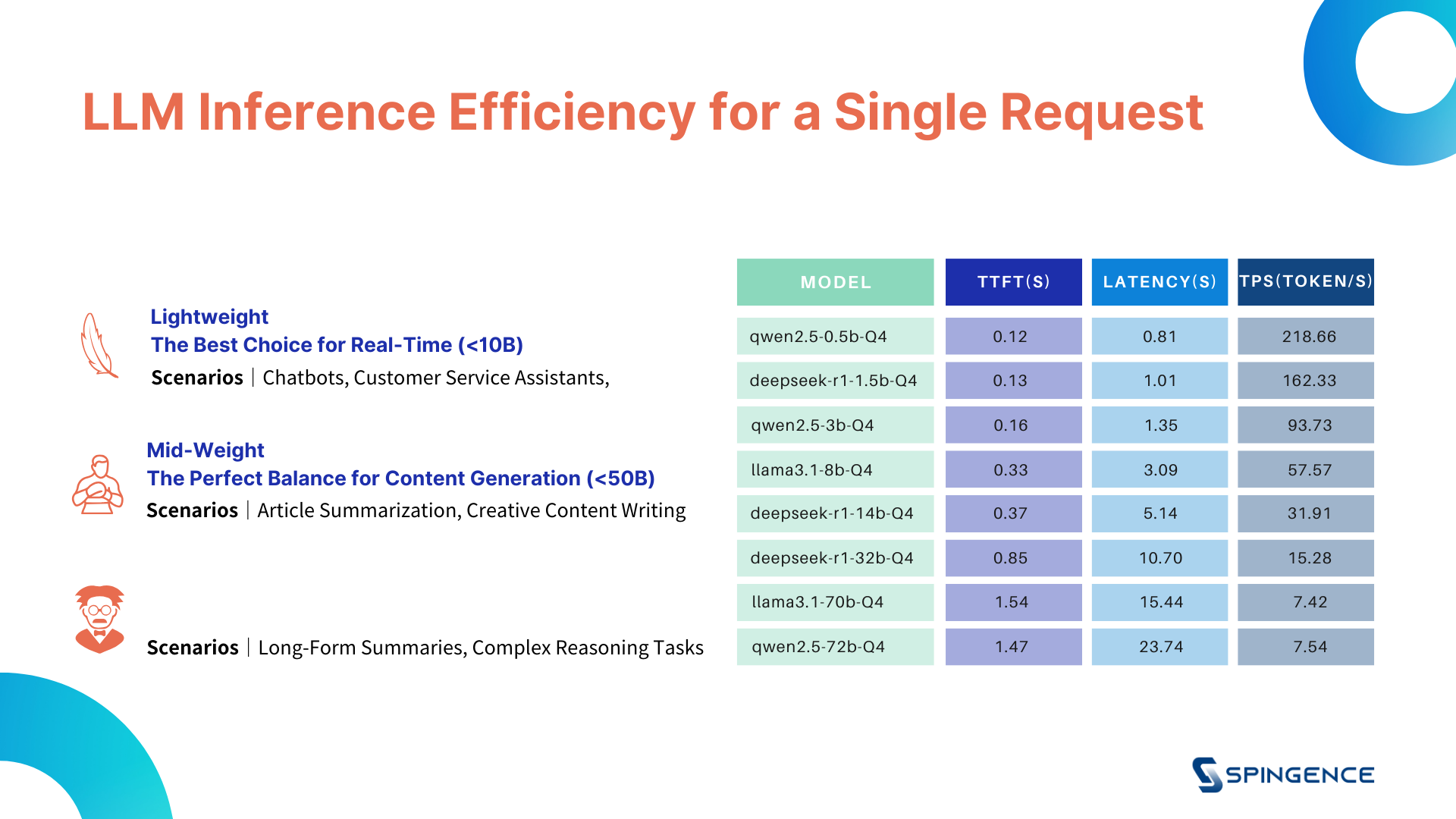
The test results show that when there is only a single request, the model’s parameter scale has a significant impact on inference efficiency. Generally, lightweight models perform faster with lower TTFT and latency, and higher TPS.
In contrast, heavyweight models require more computational resources, resulting in higher latency and lower TPS due to the increased number of parameters and more complex calculations.
In contrast, heavyweight models require more computational resources, resulting in higher latency and lower TPS due to the increased number of parameters and more complex calculations.
Impact of Concurrent Requests on LLM Inference Performance
In enterprise applications, handling not just single requests but concurrent requests from multiple users is often required. For instance, in smart customer service systems, there might be concurrent requests from dozens or hundreds of users, demanding the system’s stability and efficiency in handling high-concurrency inference tasks.
Therefore, the test includes varying concurrent request numbers (1/2/4/8/16/32/64/128) to simulate real business environments and measure the performance of each model under high load.
The following test results reveal each model's base performance under different concurrent requests and compare how models handle higher loads as the number of concurrent requests increases.
1. TTFT(Time to First Token)
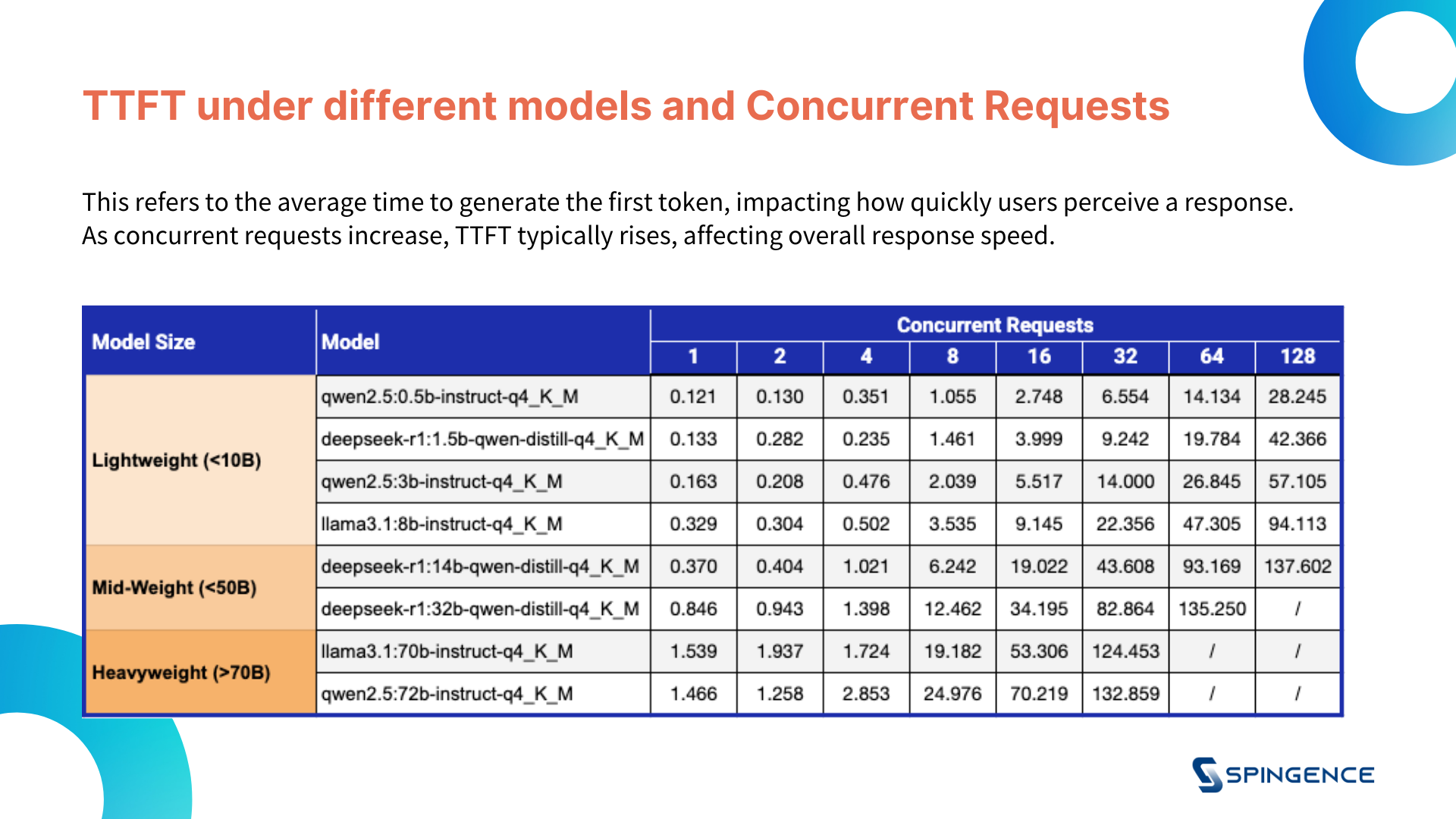
Therefore, the test includes varying concurrent request numbers (1/2/4/8/16/32/64/128) to simulate real business environments and measure the performance of each model under high load.
The following test results reveal each model's base performance under different concurrent requests and compare how models handle higher loads as the number of concurrent requests increases.
1. TTFT(Time to First Token)
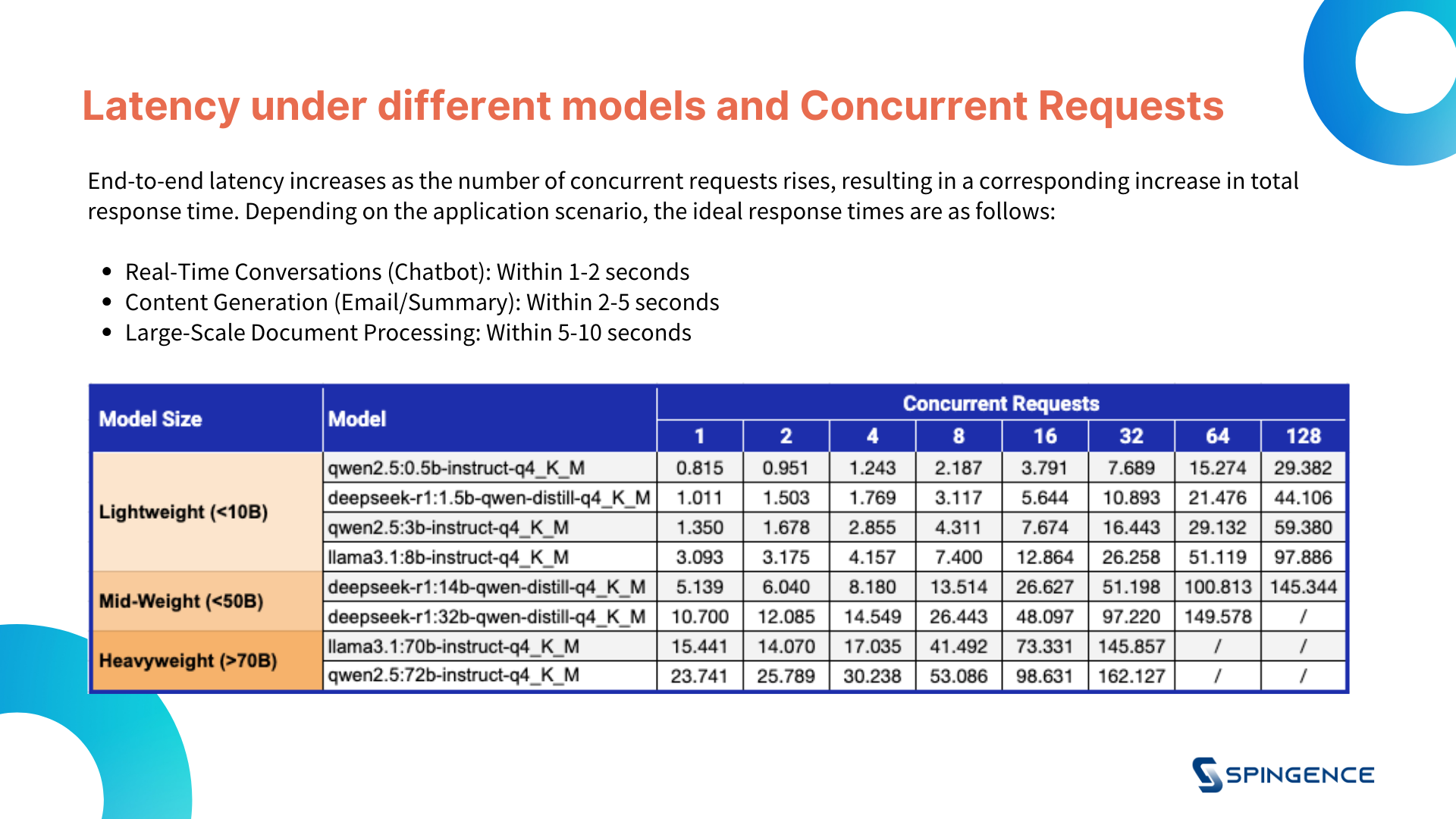
2. End-to-End Latency
3. Token per Second, TPS
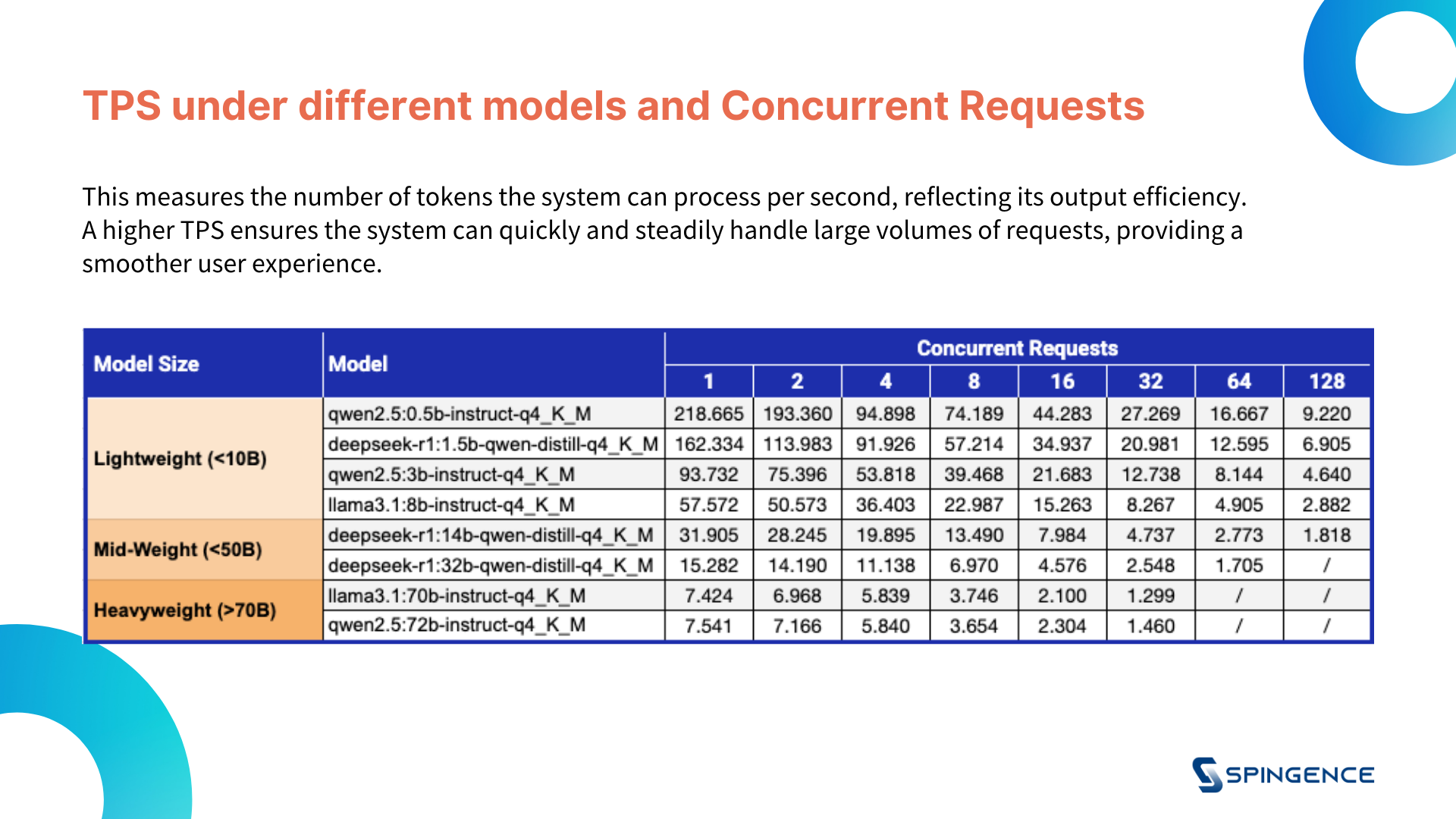
3. Token per Second, TPS
- Lightweight Models (less than 10B parameters):
- With low request numbers (such as 1 and 2 requests), lightweight models perform excellently, maintaining low TTFT and latency, and stable TPS.
- Even when the number of requests reaches 64 or 128, they can still maintain high TPS, showing good scalability.
- Ideal for applications with high response speed requirements and handling fewer concurrent requests, such as smart customer service or basic text classification
- Medium-Scale Models (less than 50B parameters):
- Medium-scale models perform slightly worse than lightweight models with low request numbers but show performance fluctuations as the request number increases. TTFT and latency significantly increase, especially at 64 and 128 requests, where the processing ability notably declines.
- Suitable for handling moderately complex tasks, such as knowledge base queries and sentiment analysis, where inference efficiency is essential.
- Heavyweight Models (greater than 70B parameters)
- Heavyweight models remain stable with low request numbers, but as the number of requests increases, end-to-end latency increases significantly, TTFT rises, and TPS drops. These models are better suited for high-concurrency request demands.
- Ideal for applications requiring extremely high model accuracy, offering precise results despite higher inference delays, and suited for high-end data analysis, large-scale content generation, and other high-demand use cases.
As enterprises increasingly rely on LLMs for business innovation, selecting the right inference solution becomes crucial.
Spingence's Edgestar platform, with its robust hardware configuration and efficient inference capabilities, helps businesses achieve stable and efficient operation when deploying LLMs locally, whether dealing with low or high concurrency workloads.
Choose Edgestar to give your enterprise a sustained performance advantage in the application of large language models.🚀
Spingence's Edgestar platform, with its robust hardware configuration and efficient inference capabilities, helps businesses achieve stable and efficient operation when deploying LLMs locally, whether dealing with low or high concurrency workloads.
Choose Edgestar to give your enterprise a sustained performance advantage in the application of large language models.🚀