
We are committed to protecting your personal data and providing you with access to your personal data in accordance with the personal data protection laws in force in the European Union. We have updated and will periodically update our privacy policy to comply with this personal data protection law. Please refer to the latest version of our Privacy Statement.
This website uses cookies to provide a better browsing experience. To learn more about how cookies are used on this site please click here.
Keep Spinning
04.12
2024
Fine-Tuning Your LLM: Tailor AI Models to Your Business Needs for Maximum Impact
Fine-Tuning Your LLM: Tailor AI Models to Your Business Needs for Maximum Impact

In the rapidly advancing world of generative AI, general-purpose language models (LLM) are powerful, but they often fail to meet the specific needs of each business. How can AI models leverage specialized fields' advantages and deliver accurate, reliable results?
The answer lies in Fine-Tuning. This technique allows you to fine-tune large pre-trained models for specific domains, significantly improving the model's specialization and accuracy. Fine-Tuning helps businesses transition from "general" to "expert" by creating AI solutions tailored to their needs, whether it's precise legal analysis, medical diagnostics, or business data interpretation.
As business demands diversify and domains become more specialized, Fine-Tuning is not just a technique for improving model performance but a key driver for AI adoption and innovative applications in enterprises.
The answer lies in Fine-Tuning. This technique allows you to fine-tune large pre-trained models for specific domains, significantly improving the model's specialization and accuracy. Fine-Tuning helps businesses transition from "general" to "expert" by creating AI solutions tailored to their needs, whether it's precise legal analysis, medical diagnostics, or business data interpretation.
As business demands diversify and domains become more specialized, Fine-Tuning is not just a technique for improving model performance but a key driver for AI adoption and innovative applications in enterprises.
What is Fine-Tuning?
LLMs (large language models) can handle various text generation tasks, such as article writing, data organization, and more. While LLMs can generate articles using prompts, the quality of their writing may not meet the standards of literary experts. This is because the pre-training process of LLMs relies on broad and diverse data aimed at solving general natural language processing tasks, rather than optimizing for a specific field or style.
To elevate LLMs to a higher level of expertise, Fine-Tuning is necessary. This process involves fine-tuning the model on data specific to a particular task or domain, allowing it to learn and specialize in the linguistic features of that field. For example, if we want an LLM to generate articles or clinical reports in the medical field, its specialized terminology, format, and writing style will differ from ordinary text. In this case, Fine-Tuning enables the model to learn medical knowledge, language habits, and report structures, thereby generating text that meets the medical domain’s requirements and achieving a high level of professionalism.
Fine-Tuning is a technique that refines pre-trained LLM models so they can perform better in specific tasks or applications. In this process, we don’t train a new model from scratch; instead, we build on an already trained model (usually trained on large amounts of general data) and re-train it with a smaller, more specialized dataset.
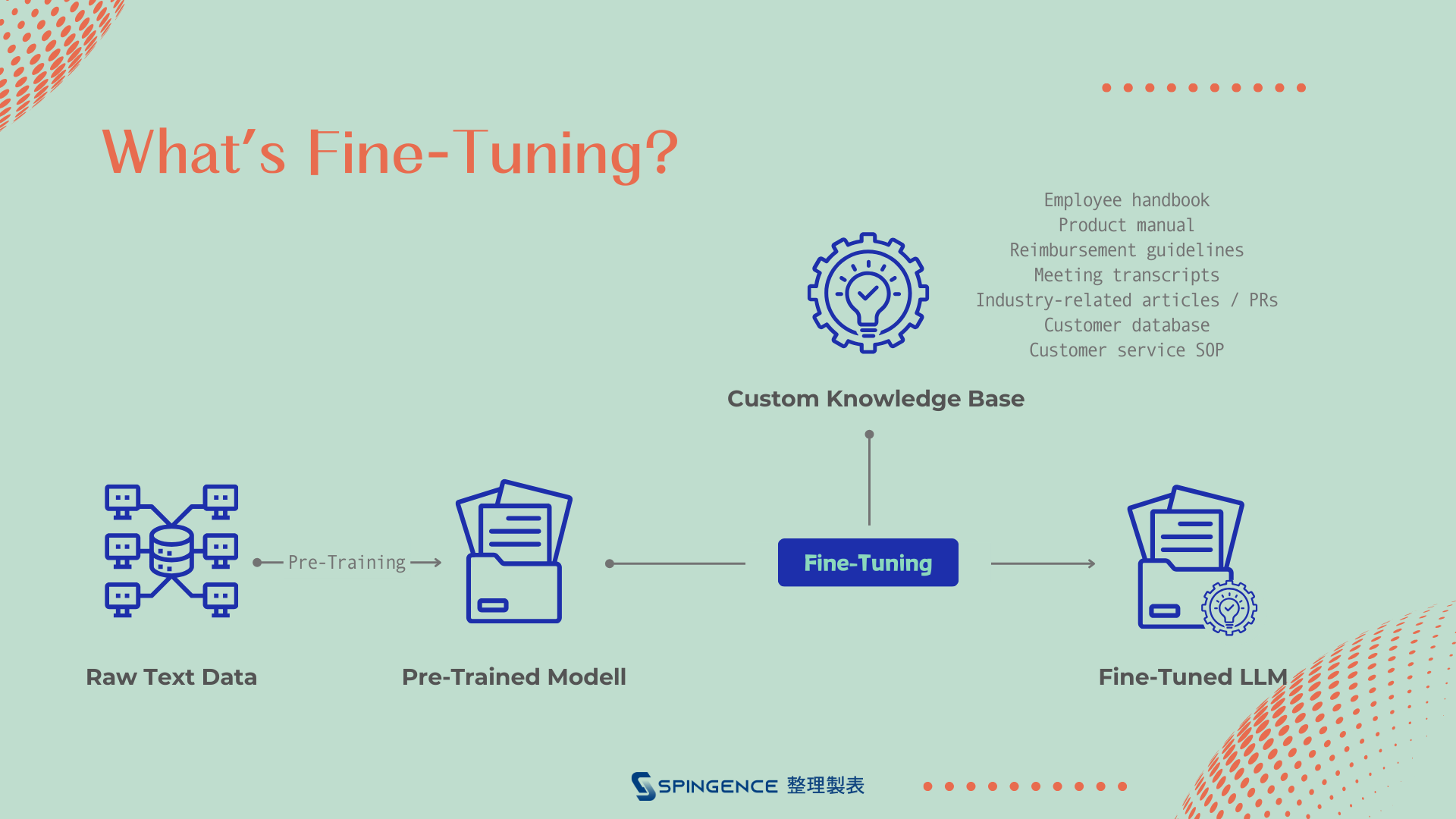
Fig. 1: Fine-tuning LLMs with highly specialized datasets enhances their ability to handle specific tasks.
Source: Compiled by Spingence.
Source: Compiled by Spingence.
Full-Parameter vs. PEFT: Choosing the Right Fine-Tuning Strategy
Two common approaches stand out when selecting a Fine-Tuning strategy: Full Parameter Fine-Tuning and Parameter Efficient Fine-Tuning (PEFT).

Fig. 2: Full-Parameter Fine-Tuning and Parameter-Efficient Fine-Tuning (PEFT) each have unique advantages and challenges.
Source: Compiled by Spingence.
Source: Compiled by Spingence.
1. Full Parameter Fine-Tuning: Comprehensive Adjustment, Comprehensive
Improvement Full Parameter Fine-Tuning involves adjusting all parameters of the pre-trained model during the fine-tuning process. This means every layer’s weights are re-trained based on new, specialized data. The main advantage of this approach is that it maximizes the model’s alignment with the specific task, often yielding the best results, particularly when the dataset is large and the domain requires a high level of expertise.
For instance, if we want a model to process highly specialized knowledge, such as medical research or legal texts, Full Parameter Fine-Tuning ensures the model understands and generates language that meets domain-specific requirements.
However, Full Parameter Fine-Tuning also presents challenges. It requires substantial computational resources and increases training costs. When working with large models (like GPT-style LLMs), the time and hardware costs can be significant.
2. Parameter Efficient Fine-Tuning (PEFT): Lightweight, Cost-Effective
In contrast, Parameter Efficient Fine-Tuning (PEFT) is a more streamlined approach, adjusting only the parameters of a few key layers while keeping most parameters unchanged. Common PEFT techniques include Adapter layers and LoRA (Low-Rank Adaptation), which add lightweight layers to the pre-trained model for fine-tuning. This strategy reduces the number of parameters that need to be trained, significantly lowering both computational costs and training time.
PEFT’s advantage lies in its cost-effectiveness, making it ideal for limited resources. Although it may not achieve the same level of performance as Full Parameter Fine-Tuning in some cases, PEFT is generally sufficient for most business applications. In practice, PEFT typically enables faster adjustments on smaller datasets while maintaining strong performance across different tasks.
Edgestar: The Most Cost-Effective Full-Parameter Fine-Tuning Solution
As a complete LLM software-hardware integration solution, Edgestar offers businesses high-performance, cost-effective Full Parameter Fine-Tuning support, with advantages such as:
- Efficient Integration
Edgestar not only provides software capabilities for Full Parameter Fine-Tuning but also includes hardware resources optimized for AI training, such as multi-GPU architectures and efficient storage solutions. This enables businesses to deploy effective training environments at a lower cost.
- Cost Advantages
Compared to other solutions on the market, Edgestar excels in balancing performance and cost. Businesses can avoid the high expenses of cloud computing resources and instead leverage dedicated LLM training infrastructure, making it a long-term investment for the enterprise.
- Ease of Use and Flexibility
Edgestar's software features an intuitive user interface and automated processes, lowering the technical barriers to Full Parameter Fine-Tuning. Even businesses without specialized AI talent can easily get started.
Choosing the Right Fine-Tuning Strategy to Achieve Business Goals
Whether opting for Full Parameter Fine-Tuning or PEFT, each Fine-Tuning approach has its unique advantages and challenges. Therefore, businesses should consider factors such as task complexity, dataset size, budget, and computational resources when selecting the appropriate fine-tuning strategy. Choosing the most suitable Fine-Tuning method will help businesses enhance model performance while achieving the best balance of cost-effectiveness. This not only strengthens the core competitive advantage of the business but also ensures long-term success in the AI field amid fierce market competition.
Recommended Reading: How Edgestar’s Hardware Specifications Meet Full-Parameter LLM Fine-Tuning Needs