
We are committed to protecting your personal data and providing you with access to your personal data in accordance with the personal data protection laws in force in the European Union. We have updated and will periodically update our privacy policy to comply with this personal data protection law. Please refer to the latest version of our Privacy Statement.
This website uses cookies to provide a better browsing experience. To learn more about how cookies are used on this site please click here.
Keep Spinning
04.12
2024
Exploring LLM Enhancement Strategies: Prompt Engineering, RAG, and Fine-Tuning
Exploring LLM Enhancement Strategies: Prompt Engineering, RAG, and Fine-Tuning

Large language models (LLMs) form the backbone of many AI applications, but their pre-trained capabilities often fall short in specific scenarios. To address this challenge, three technical strategies—Prompt Engineering, Retrieval-Augmented Generation (RAG), and full-parameter Fine-Tuning—are widely adopted to optimize LLM performance.
This article delves into the principles, applications, advantages, and limitations of these three approaches, exploring how their integration can balance consistency, stability, and cost-effectiveness.
This article delves into the principles, applications, advantages, and limitations of these three approaches, exploring how their integration can balance consistency, stability, and cost-effectiveness.
Prompt Engineering:Flexible Optimization at Minimal Cost
Prompt Engineering involves designing input prompts to guide the model's outputs. This method relies solely on the model's pre-trained knowledge and does not alter internal parameters.

Figure 1: Prompt Engineering enables flexible optimization of LLM performance at minimal cost. Source: Compiled and charted by Spingence
Application
- Rapid Prototype Development: Quickly adjust outputs for concept validation or application testing.
- User-Friendly Operation: Non-technical users can easily adjust prompts to achieve varied results.
Advantages and Limitations
- Advantages: Low cost, high flexibility, and immediate applicability across various scenarios.
- Limitations: Results are limited by the model's existing knowledge and capabilities, unsuitable for high-precision or domain-specific needs.
RAG: Real-Time Solutions with External Knowledge
RAG combines LLMs with external retrieval systems, enabling the model to reference real-time information from external sources (e.g., databases, web pages) for broader knowledge coverage.

Figure 2: RAG enhances LLM performance by integrating external knowledge. Source: Compiled and charted by Spingence.
Applications
- Dynamic Knowledge: Ideal for generating answers based on the latest information, such as news interpretation or regulatory inquiries.
- Knowledge-Intensive Industries: Fields like healthcare diagnostics or legal document analysis benefit from RAG's specialized support.
Advantages and Limitations
- Advantages: Overcomes static knowledge limitations and adapts to rapidly changing demands.
- Limitations: Relies heavily on retrieval system performance and the quality and consistency of external databases, requiring additional retrieval pipelines.
Fine-Tuning: Deep Specialization and Consistency
Fine-Tuning alters an LLM's internal parameters through additional training, enabling it to excel in specific tasks with greater professionalism and stability. Training data often includes domain-specific content or application-specific linguistic styles.

Figure 3: Fine-Tuning meets enterprise demands for professional and consistent LLM outputs. Source: Compiled and charted by Spingence.
Applications
- Long-Term Deployment: Tasks requiring consistent, specialized outputs, such as customer service systems or professional document generation.
- Diverse Needs: Applications requiring specific formats, tones, or styles.
Advantages and Limitations
- Advantages: Highly consistent outputs, seamlessly integrated into specialized domains, with lower operational costs compared to continuous RAG reliance.
- Limitations: Requires high-quality training data, substantial computational resources, and time.
Combining the Three: A Holistic LLM Solution
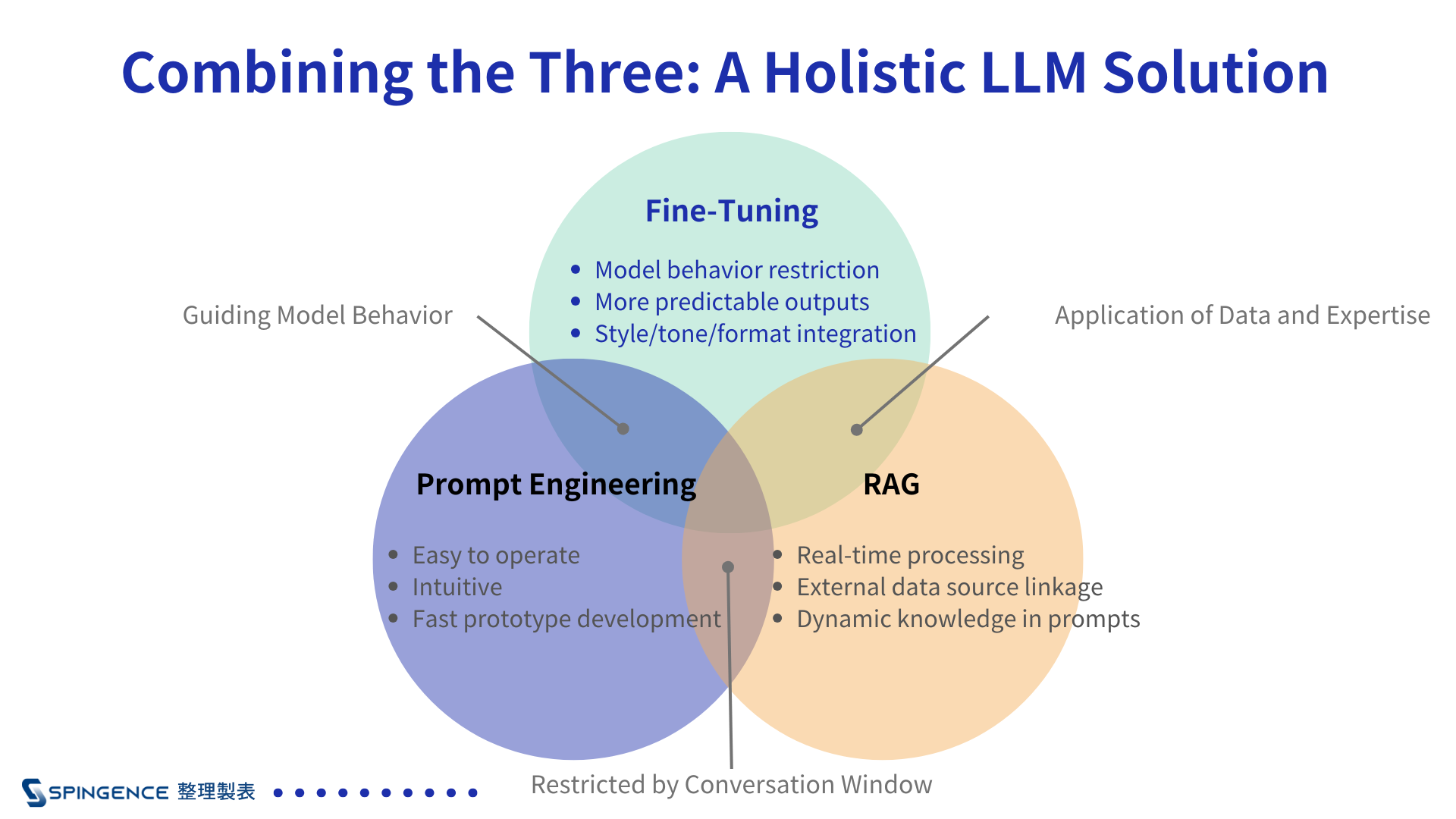
Figure 4: Combining the three strategies offers a comprehensive LLM solution, delivering rapid and specialized outputs within limited budgets. Source: Compiled and charted by Spingence.
Though distinct, these strategies can complement each other in application:
1. Prompt Engineering and RAG for Rapid Prototyping
1. Prompt Engineering and RAG for Rapid Prototyping
Early-stage development benefits from Prompt Engineering's flexibility paired with RAG's real-time knowledge.
2. Fine-Tuning for Stability
Fine-Tuning embeds critical expertise directly into the model, reducing dependency on external retrieval systems and ensuring stable, consistent outputs.
3. Balancing Cost and Efficiency
Combining Prompt Engineering and RAG for quick optimization with Fine-Tuning for long-term stability lowers overall costs while enhancing user experience.
The Industrial Value of LLM-Driven Technology
Prompt Engineering, RAG, and Fine-Tuning serve as the foundational pillars of LLM applications, excelling in flexibility, knowledge extension, and specialization. By combining these strategies, businesses can better meet operational needs, enhancing stability and efficiency.
As LLM technology evolves, integrating these methods will further improve model performance, offering efficient, customized solutions for diverse industries.
Recommended Reading:
Edgestar supports full-parameter Fine-Tuning, empowering enterprises to build customized LLMs while significantly enhancing model performance and efficiency, making it the ideal partner to tackle future challenges.